
Equivariance is dead, long live equivariance?
When should you bake symmetries into your architecture versus just scaling up — an attempt at a nuanced take for molecular modelling.


tl;dr: I think roto-translation equivariance is still relevant for molecular simulation and property prediction problems. Diffusion-based generative models, on the other hand, are likely to move away from equivariance in favour of scaling.
I’m currently writing my PhD thesis, tentatively titled “Geometric Deep Learning for Molecular Modelling and Design“. As I look back over the past three and a half years, a central theme of my research has been the interplay between the physical symmetries that govern molecular systems and whether to implement these symmetries as inductive biases in deep learning architectures.
Through this post, I want to discuss the engineering and computational aspects of molecular modelling, particularly the notion of the hardware lottery — the marriage of architectures and hardware that determines which research ideas rise to prominence. These discussions focus on Transformers versus Graph Neural Networks, and roto-translation equivariance versus learning symmetries at scale, which are the two main architectural paradigms in my research.1
Transformers are winning the hardware lottery
Transformers are GNNs which implement a fully-connected message passing scheme via dense matrix multiplications. In contrast, GNNs typically implement sparse message passing over locally connected structures. Sparse message passing operations are significantly slower on GPUs for size ranges of typical molecular systems. Modern GPUs are hyper-optimised for dense computation.
For molecular modelling, the state-of-the-art architecture is generally an Equivariant GNN.2 The best models rely on higher-order tensor representations to achieve maximum expressivity while preserving roto-translation symmetries. This results in a significant increase in memory usage and computational complexity, making equivariant networks orders of magnitude slower to train and scale up than standard Transformers on current hardware.
The evolution from AlphaFold2 to AlphaFold3 exemplifies a paradigm shift in recent years. AlphaFold3's architecture is a lot simpler compared to AlphaFold2, which explicitly incorporated roto-translation equivariance when predicting 3D coordinates of protein structures. Instead, AlphaFold3 uses a Transformer-based architecture and data augmentation when learning to predict 3D coordinates. This approach is easier to scale and generalises naturally to all-atom biomolecular complexes. AlphaFold3 is a very effective demonstration of geometric symmetries learnt at scale using a sufficiently expressive model.
In the near term, the hardware lottery will likely lead to favouring Transformers. If you believe in scaling and want to train molecular foundation models with billions of parameters on large datasets, a Transformer would probably be the architecture of choice. Training equivariant networks at such scales would simply be prohibitively expensive at present.
There’s a lot more nuance to this discussion, though.
A problem-centric approach to architectures
It would be naive to conclude that equivariant networks are inferior to unconstrained architectures — the choice of inductive biases depends fundamentally on the problem at hand.
Case 1: Interatomic potentials for molecular dynamics
When data is limited or strict symmetry guarantees are essential — such as in molecular property prediction and dynamics simulation — explicitly enforcing symmetries provides greater data efficiency and generalization. For instance, equivariant GNNs with higher-order tensors are the current state-of-the-art in interatomic potentials for molecular simulation.
What’s the intuition here? For most practical applications in molecular simulations, models must learn physically meaningful and smooth energy landscapes—here, local interactions and equivariant representations that transform predictably under roto-translation provide essential inductive biases for capturing the underlying physics.3

In contrast, when large-scale training data is available and exact symmetry guarantees are not crucial, implicit or learned symmetry constraints can have an advantage. Diffusion-based generative models exemplify this scenario.
Case 2: Generating molecular structure with diffusion
In diffusion models, a denoiser network learns the underlying data distribution by observing molecular structures under varying noise levels and iteratively reconstructing valid configurations. What matters most is that the denoiser produces valid molecular structures given noisy inputs. If the denoiser produces different outputs from rotated versions of the same noisy input, this may not be problematic as long as both outputs represent physically plausible structures.
Again, What’s the intuition? If you’ve trained some diffusion models, you may agree that learning from each sample in the data distribution under different noise levels is crucial for optimal generative modelling. This boils down to performing as many epochs of training as possible with a sufficiently expressive denoiser, as approximate roto-translation equivariance often emerges in unconstrained networks when trained at scale. Since the noisy intermediate steps do not represent physically meaningful structures, the inductive biases of explicit equivariance and locality become less critical.
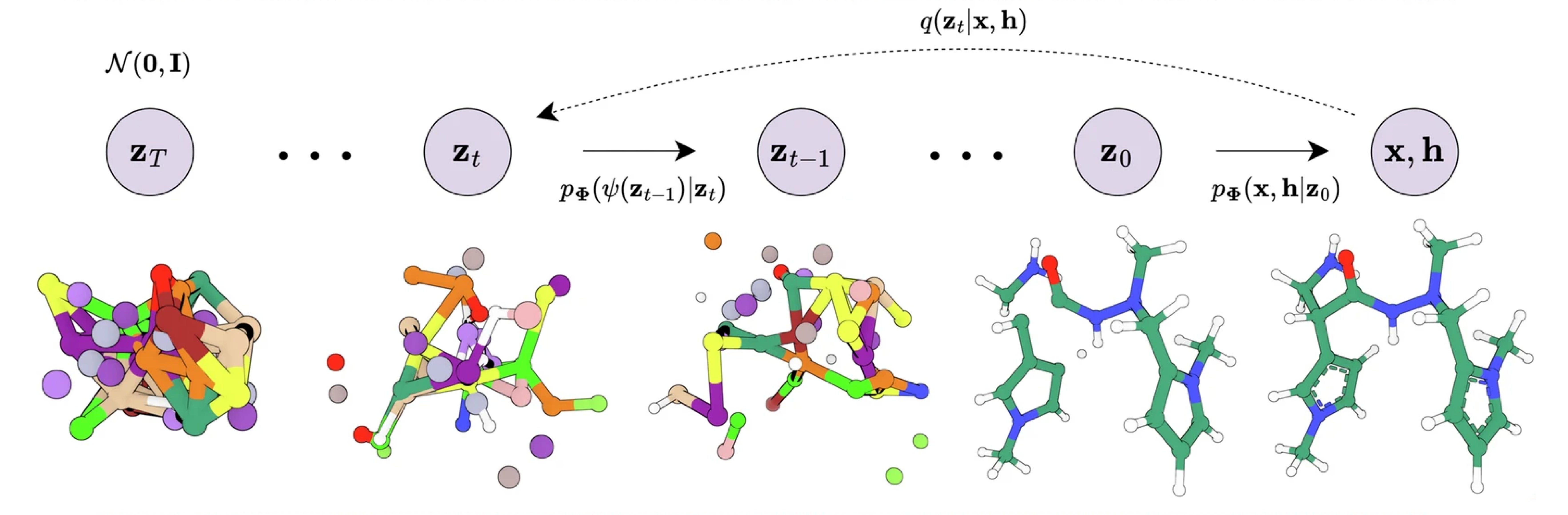
This phenomenon helps explain the strong performance of recent Transformer-based diffusion models for molecular generation.4 The hardware lottery enables Transformers to be trained for many more iterations than equivariant networks within the same computational budget, leading to improved performance.
Closing thoughts
Overall, roto-translation equivariance is a powerful inductive bias and strong guarantee of physical correctness. However, equivariance can also be viewed as a hard constraint that ultimately limits model expressivity. A similar argument can be made regarding locality.5
Here’s a pragmatic perspective that I’d like to leave you with: Architectures are tools for solving problems. The choice of architecture should be driven by the problem at hand, the available data and the computational resources.
In other words, the best models are the ones you can train today!
Responses
Here’s my original post on X sharing this blogpost, and responses from researchers working on related areas, including Michael Bronstein, Jason Yim, and Hannes Stärk.
I want to highlight and respond to a few common themes.
On smoothness of energy landscapes and efficiency in MLIPs
Ilyes Batatia (PhD student at Cambridge University) wrote back with his thoughts, which lead to a great discussion with Mark Neumann (Head of ML, Orbital Materials). Mark then wrote an excellent blogpost on equivariance, too: full post and thread.
I thought Mark’s post was filled with even more insights than my attempt here. An especially important point of discussion (on which I may well be wrong) is that equivariant representations such as spherical harmonics act as a useful inductive bias for learning smooth and physically realistic energy landscapes. Tim Duignan (also at Orbital Materials) wrote back with strong arguments for why these two properties are not necessarily linked.
Reading Mark and Tim’s responses makes me re-think my intuitions a bit. It may be possible to learn smooth and smoothly differentiable energy landscapes without equivariant intermediate representations. The next version of Orb will probably break my intuitions, which I look forward to ;)
On equivariant diffusion models
Erik Bekkers (Professor at University of Amsterdam) wrote an insightful response and shared his lab’s recent work on carefully ablating equivariant and non-equivariant diffusion denoisers.
Their findings seem to contradict my intuitions, yet again. They argue that parameter-matched equivariant networks show better scaling properties than unconstrained denoiosers (though I would argue that FLOPS or wall clock time are more practical x-axis measures in scaling experiments).
I agree with Mark’s response to Erik around how the choice of datasets can influence the conclusions from scaling studies. The dataset, the number of GPUs one parallelizes across, and the resulting wall clock times for different architectures are all important considerations when setting up scaling studies.
Based on Erik’s paper, I think the best choice of denoiser architecture may also be highly problem-specific.
On all roads leading to autoregressive Transformers
Finally, Alán Aspuru-Guzik (Professor at University of Toronto) wrote a comment on LinkedIn sharing a recent opinion article they wrote about similar themes, as well as their work on purely autoregressive, GPT-style Transformers generating molecules and crystals as pure text. They also released a diffusion-augmented variant recently.
Considering that Alán and his lab have been extremely prescient / ahead of the curve over the years when it comes to molecular design, things may well play out as he hints. Personally, I’m a bit biased towards diffusion at the moment / in the near term, but perhaps in the long run the more general paradigm of text prompt as input → direct generation will win out, as it has done across broader AI research and applications.
Its important to caveat that both Transformers and GNNs also bake in the inductive bias of permutation equivariance over sets of inputs (and use positional encodings when handling ordered inputs). I think permutation symmetry will continue to be an important inductive bias in architectures for molecules and beyond.
Depending on whether local interactions are a useful inductive bias, Equivariant GNNs may operate on sparse graphs or consider all pairwise interactions.
Notable examples of this paradigm include MACE from Cambridge and UMA from FAIR Chemistry. Two recent papers have also discussed these intuitions in great detail with similar conclusions: eSEN and The dark side of forces.
Some examples are Molecular Conformer Fields from Apple, AlphaFold3 from DeepMind, and All-atom Diffusion Transformers, from FAIR Chemistry and yours truly.
This echos the Bitter Lesson of AI research, seemingly playing out yet again. However, if you go and listen to John Jumper’s Nobel Prize speech, its all about building in the right inductive biases.